Agentic LLMs with web search change the threat model for text anonymization: weak
contextual cues can become cross-referenceable evidence for re-identification, yet those
same details also carry downstream analytic value of the text. Existing defenses either
remove explicit identifiers, perturb text for formal privacy, or test rewritten text
against non-web inference models, leaving underexplored the operating region between
resistance to agentic web-search re-identification and utility retention.
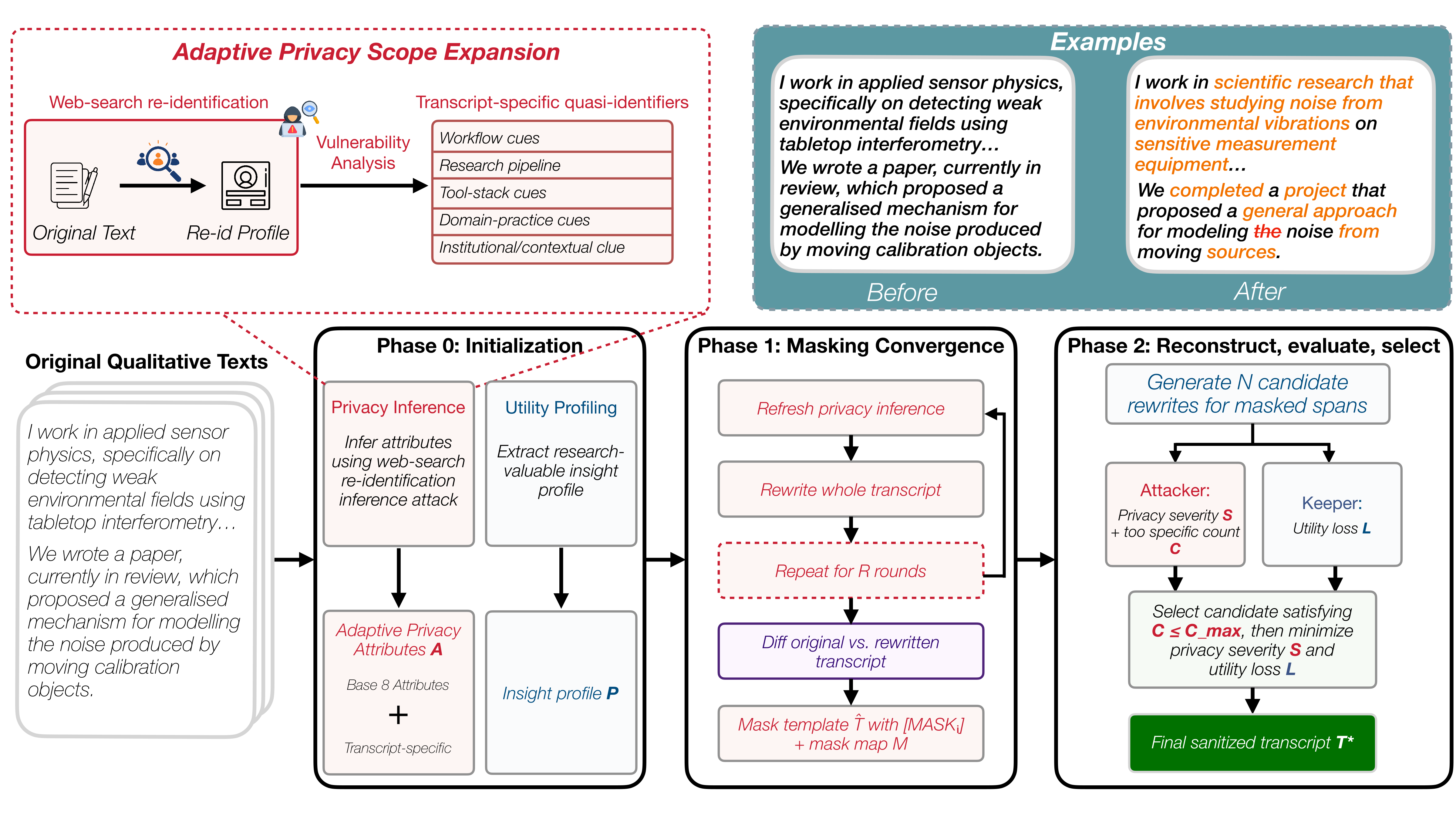
We introduce AURA (Anonymization with
Utility-Retention Adaptation), an
LLM-powered mask–reconstruct framework that decouples privacy localization from
utility-preserving reconstruction and selects candidates with adversarial privacy and
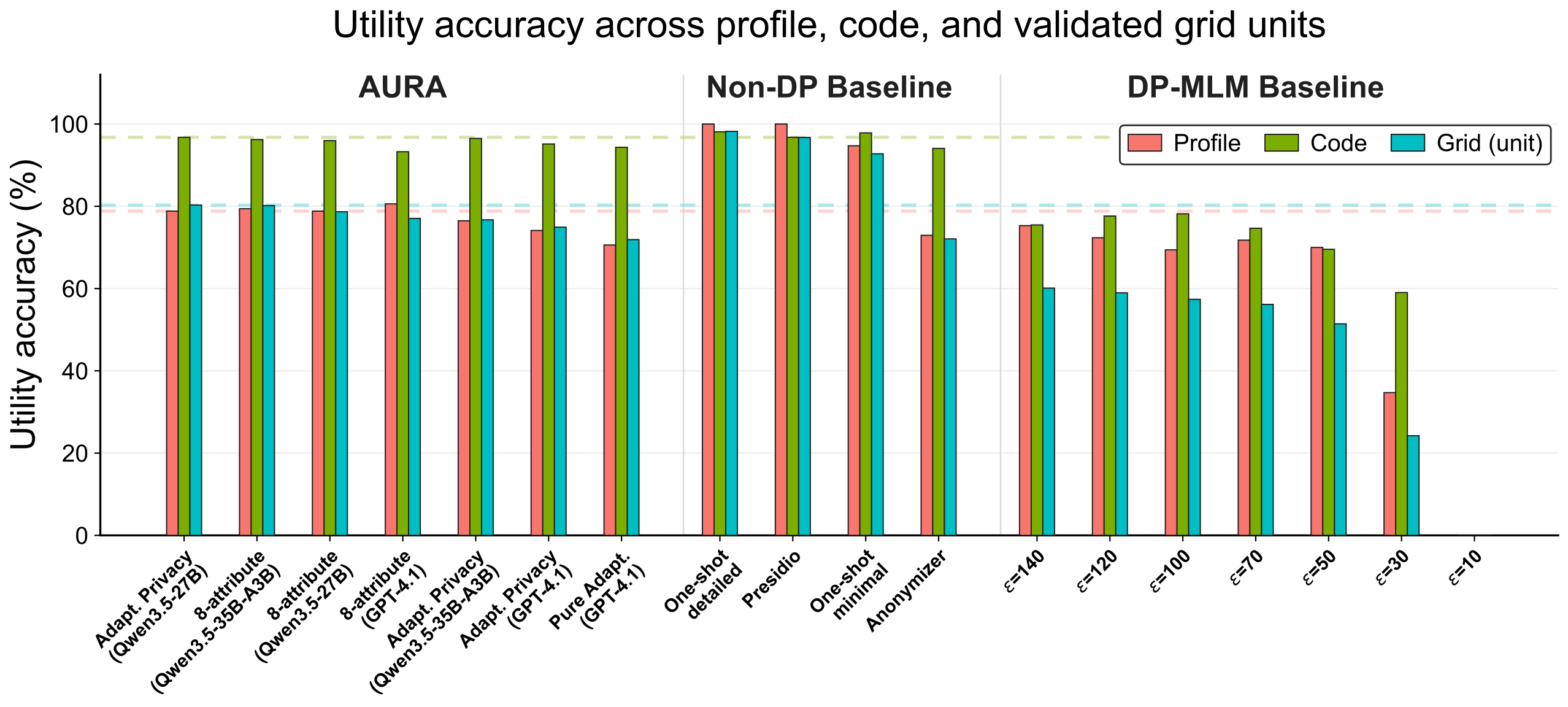
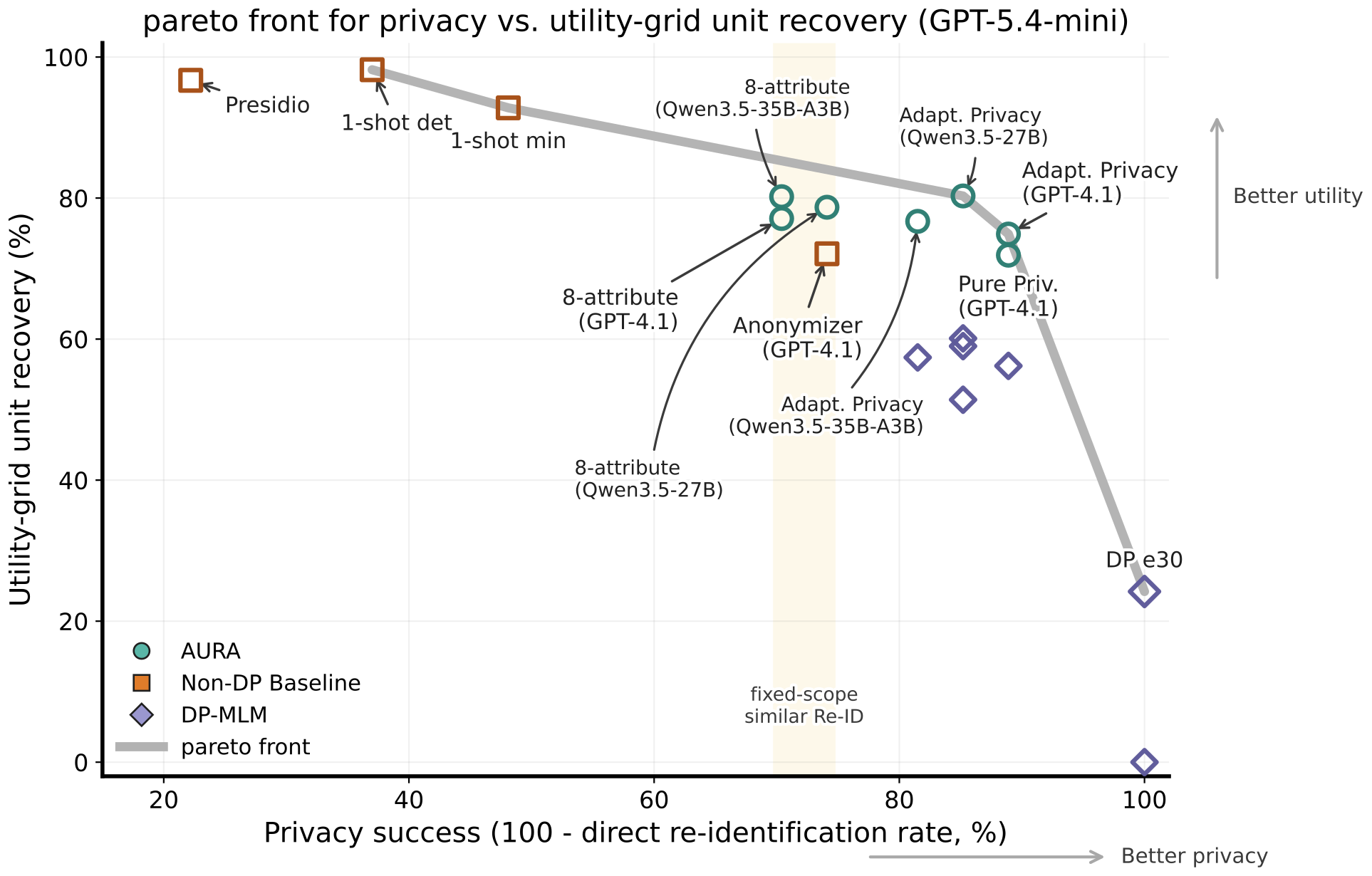
utility-retention checks. We evaluate AURA on real-user
interview transcripts using re-identification attacks carried out by web-search agents,
along with a utility evaluation based on interviewee-profile facts, codebook facts, and
the joint contextual utility grid. Our results show that
AURA improves the privacy-utility frontier by using
adaptive privacy scope to strengthen resistance to agentic re-identification and using a
mask–reconstruct anonymization method to better preserve contextual utility under fixed
privacy scope.